最近在研究 AI 相关的系统,发现一个常见的需求,就是如何让 Ollama 和 LM Studio 禁止思考和推理输出。这个在工具链调用中是完全不必要的,甚至在自用的场合都觉得很烦,我不想看啊,只想知道结果。这个输出很慢的,好些时候,比直接给结果还慢好几倍。
先问的AI自己,这么说的:
你可以通过在提问时明确指示模型“只输出答案,不要解释”或“禁止输出思考过程”,来引导 Qwen 模型仅返回最终答案。例如:
“请只给出答案,不要任何推理或解释。”
“答案是什么?不要说明过程。”
“直接输出结果。”此外,在程序调用 API 时,也可以通过设置系统提示(system prompt)来全局约束模型行为,例如:你是一个简洁回答助手,永远只输出最终答案,不包含任何推理、解释、前缀或后缀。
不管用,没有任何作用。
经过一番研究,我找到了解决办法。
如果使用Ollama,这样用:
ollama run qwen3.5:4b --think=false
这就从命令行中禁止了思考过程输出。在 Ollama 命令行执行后,还可以使用 /set 命令进行设置:
/set nothink
这也是生效的。
LM Studio 以图形操作为特色,需要修改模型的模板配置,在 LM Studio 的“我的模型”页面设置。
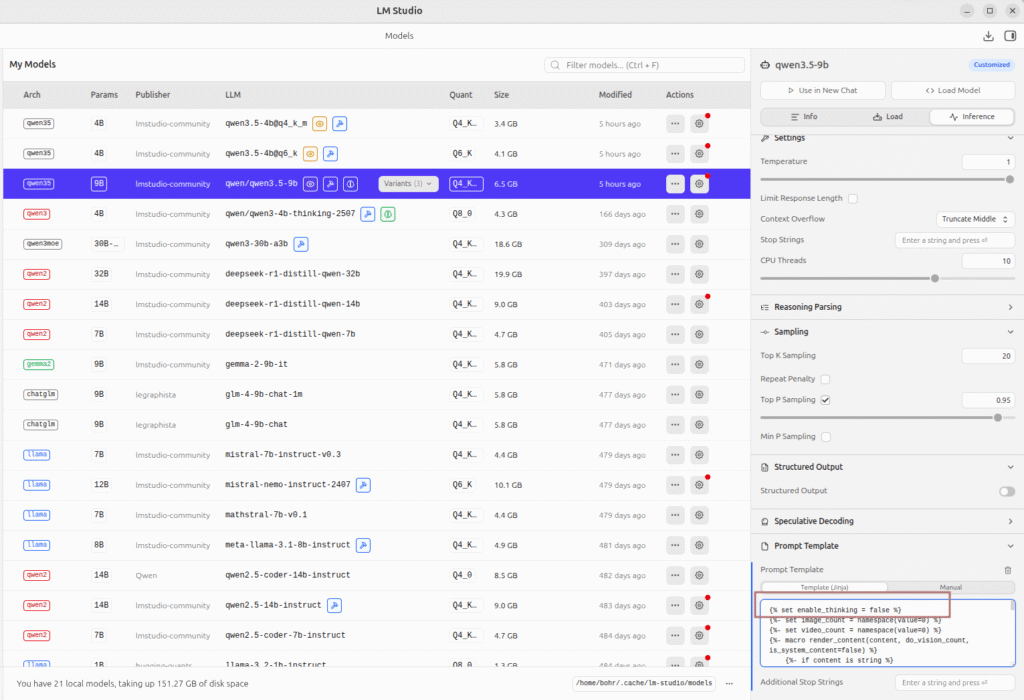
在模板的第一行加上:
{%- set enable_thinking = false %}
这是因为,模板最后面有一个设定:
{%- if add_generation_prompt %}
{{- ‘<|im_start|>assistant\n’ }}
{%- if enable_thinking is defined and enable_thinking is false %}
{{- ‘<think>\n\n</think>\n\n’ }}
{%- else %}
{{- ‘<think>\n’ }}
{%- endif %}
{%- endif %}
重新加载模型,如此便解决了问题。
如果你在外面网站上看到一样的解答,那是因为那个答案就是我写的。
